[ad_1]
Lacking values are frequent and happen both as a result of human error, instrument error, processing from one other group, or in any other case only a lack of information for a sure statement.
On this Byte, we’ll check out the way to fill NaNs in a
DataFrame, in case you select to deal with NaNs by filling them.
First off, let’s create a mock DataFrame with some random values dropped out:
import numpy as np
array = np.random.randn(25, 3)
masks = np.random.selection([1, 0], array.form, p=[.3, .7]).astype(bool)
array[mask] = np.nan
df = pd.DataFrame(array, columns=['Col1', 'Col2', 'Col3'])
Col1 Col2 Col3
0 -0.671603 -0.792415 0.783922
1 0.207720 NaN 0.996131
2 -0.892115 -1.282333 NaN
3 -0.315598 -2.371529 -1.959646
4 NaN NaN -0.584636
5 0.314736 -0.692732 -0.303951
6 0.355121 NaN NaN
7 NaN -1.900148 1.230828
8 -1.795468 0.490953 NaN
9 -0.678491 -0.087815 NaN
10 0.755714 0.550589 -0.702019
11 0.951908 -0.529933 0.344544
12 NaN 0.075340 -0.187669
13 NaN 0.314342 -0.936066
14 NaN 1.293355 0.098964
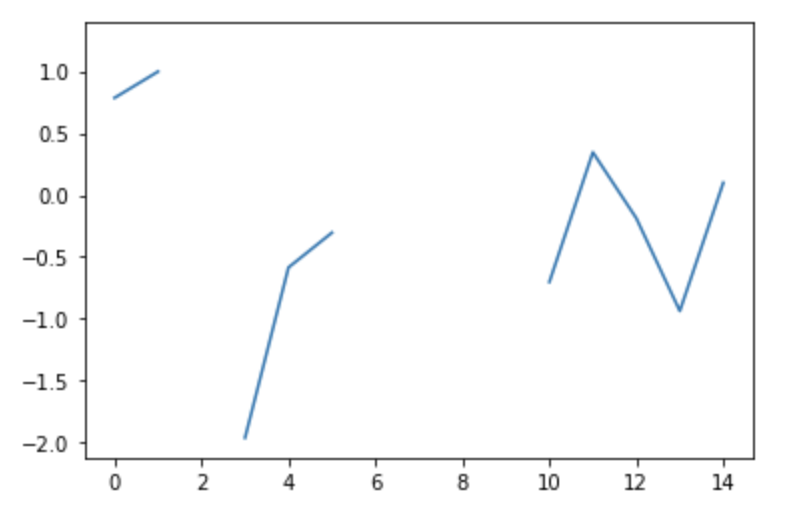
Let’s plot, say, the third column:
plt.plot(df['Col3'])
When full of varied strategies – this NaN-filled graph may be changed with:

fillna() – Imply, Median, Mode
You possibly can fill these values into a brand new column and assign it to the column you want to fill, or in-place utilizing the inplace argument. Right here, we’ll be extracting the stuffed values in a brand new column for ease of inspection:
imply = df['Col3'].fillna(df['Col3'].imply(), inplace=False)
median = df['Col3'].fillna(df['Col3'].median(), inplace=False)
mode = df['Col3'].fillna(df['Col3'].mode(), inplace=False)
The median, imply and mode of the column are -0.187669, -0.110873 and 0.000000 and these values will probably be used for every NaN respectively. That is successfully filling with fixed values, the place the worth being enter depends upon the entiery of the column.
First, filling with median values ends in:

With imply values:

With mode values:

fillna() – Fixed Worth
You can even fill with a continuing worth as an alternative:
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and really study it!
fixed = df['Col3'].fillna(0, inplace=False
This ends in a continuing worth (0) being put as an alternative of every NaN. 0 is near our median and imply and equal to the mode, so the stuffed values will resemble that technique carefully for our mock dataset:
0 0.783922
1 0.996131
2 0.000000
3 -1.959646
4 -0.584636
5 -0.303951
6 0.000000
7 1.230828
8 0.000000
9 0.000000
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

fillna() – Ahead and Backward Fill
On every row – you are able to do a ahead or backward fill, taking the worth both from the row earlier than or after:
ffill = df['Col3'].fillna(technique='ffill')
bfill = df['Col3'].fillna(technique='bfill')
With forward-filling, since we’re lacking from row 2 – the worth from row 1 is taken to fill the second. The values propagate ahead:
0 0.783922
1 0.996131
2 0.996131
3 -1.959646
4 -0.584636
5 -0.303951
6 -0.303951
7 1.230828
8 1.230828
9 1.230828
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

With backward-filling, the other occurs. Row 2 is full of the worth from row 3:
0 0.783922
1 0.996131
2 -1.959646
3 -1.959646
4 -0.584636
5 -0.303951
6 1.230828
7 1.230828
8 -0.702019
9 -0.702019
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

Although, if there’s a couple of NaN in a sequence – these will not do effectively and may cascade NaNs additional down, skewing the info and eradicating truly recorded values.
interpolate()
The interpolate() technique delegates the interpolation of values to SciPy’s suite of strategies for interpolating values. It accepts all kinds of arguments, together with, nearest, zero, slinear, quadratic, cubic, spline, barycentric, polynomial, krogh, piecewise_polynomial, spline, pchip, akima, cubicspline, and so on.
Interpolation is far more versatile and “sensible” than simply filling values with constants or half-variables equivalent to earlier strategies.
Interpolation can correctly fill a sequence in a manner that no different strategies can, equivalent to:
s = pd.Sequence([0, 1, np.nan, np.nan, np.nan, 5])
s.fillna(s.imply()).values
s.fillna(technique='ffill').values
s.interpolate().values
The default interpolation is linear, and assuming that 1...5 is probably going a 1, 2, 3, 4, 5 sequence is not far-fetched (however is not assured). Each fixed filling and ahead or backward-filling fail miserably right here. Usually talking – interpolation is normally going to be a great good friend with regards to filling NaNs in noisy alerts, or corrupt datasets.
Experimenting with forms of interpolation could yield higher outcomes.
Listed below are two interpolation strategies (splice and polynomial require an order argument):
nearest = df['Col3'].interpolate(technique='nearest')
polynomial = df['Col3'].interpolate(technique='polynomial', order=3)
These end in:

And:

[ad_2]
Source_link