[ad_1]
In our earlier Python tutorial, now we have defined tips on how to develop Consumer Administration System with Python, Flask and MySQL. On this tutorial, we are going to clarify tips on how to do internet scraping utilizing Python.
Now the query arises, What’s Internet Scraping? Internet Scraping is a course of to extract information from web sites. The scraping software program make request to web site or internet web page and extracts underlying HTML code with information to make use of additional in different web sites.
On this tutorial, we are going to focus on tips on how to carry out internet scraping utilizing the requests and beautifulsoup library in Python.
So let’s proceed to do internet scraping.
Software Setup
First, we are going to create our software listing web-scraping-python utilizing beneath command.
$ mkdir web-scraping-python
we moved to the mission direcotry
$ cd web-scraping-python
Set up Required Python Library
We want requests and beautifulsoup library from Python to do scraping. So we have to set up these.
- requests: This modules offers strategies to make HTTP request (GET, POST, PUT, PATCH, or HEAD requests). So we’d like this to make
GETHTTP request to a different web site. We’ll set up it utilizing the beneath command:
pip set up requests
- beautifulsoup: This library used to parsing HTML and XML paperwork.. We’ll set up it utilizing the beneath command:
pip set up beautifulsoup
Making HTTP Request to URI
We’ll make HTTP GET request from given server to URI. The GET methodology sends the encoded data with the web page request.
# Import requests library
import requests
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/")
print (req.content material)
After we make a request to URI, it returns a response object. The response object have many capabilities (status_code, url, content material) to get particulars of request and response.
Output :
Scrape Info utilizing BeautifulSoup Library
We’ve response information object after making HTTP request to URI. However response information nonetheless not helpful because it must parse to extract usefull information.
So now we are going to parse that response information utilizing BeautifulSoup library. We’ll embody BeautifulSoup library and parse the response HTML utilizing library.
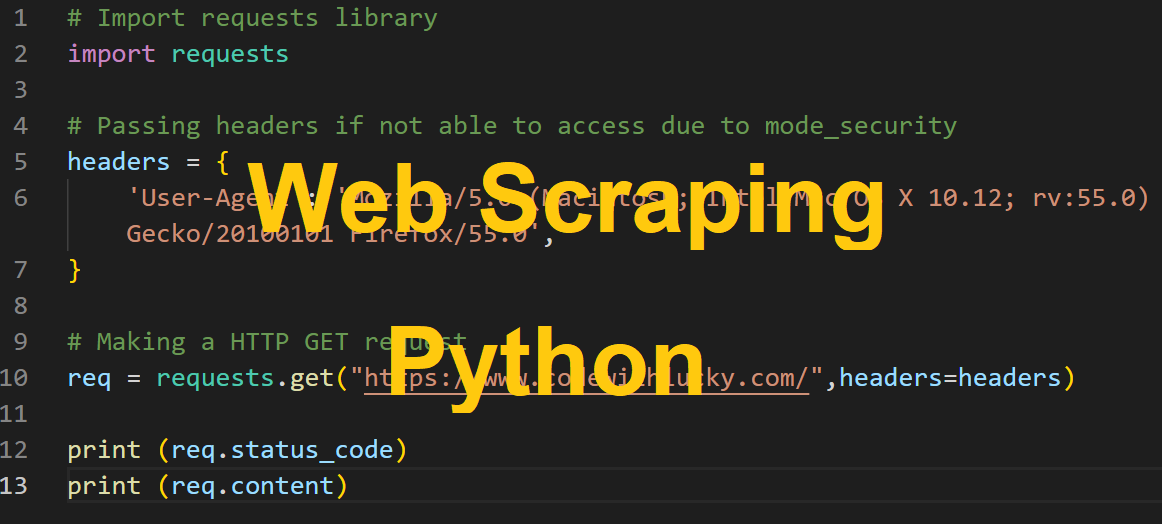
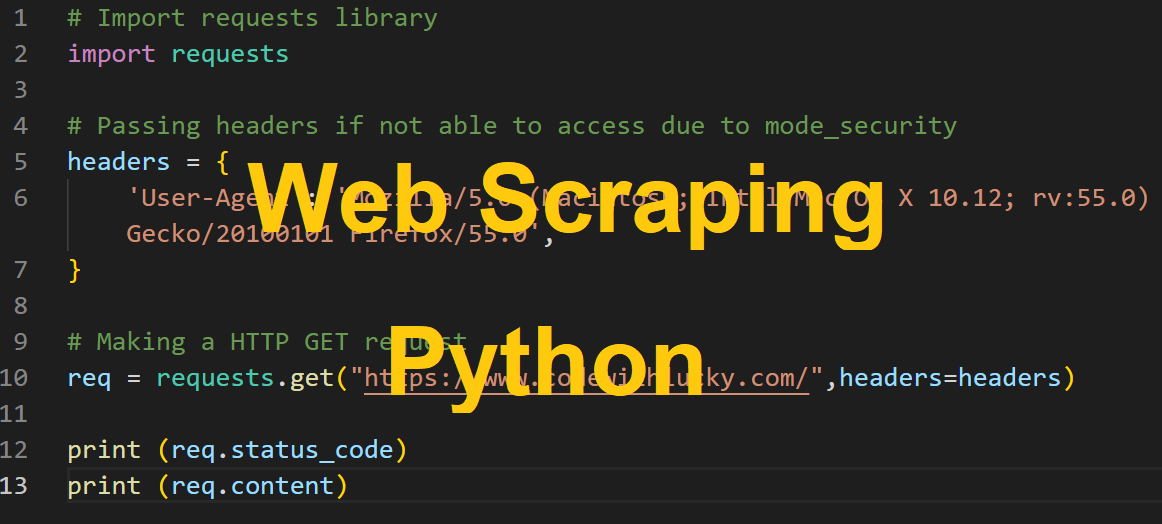
import requests
from bs4 import BeautifulSoup
# Passing headers if not in a position to entry as a result of mode_security
headers = {
'Consumer-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/",headers=headers)
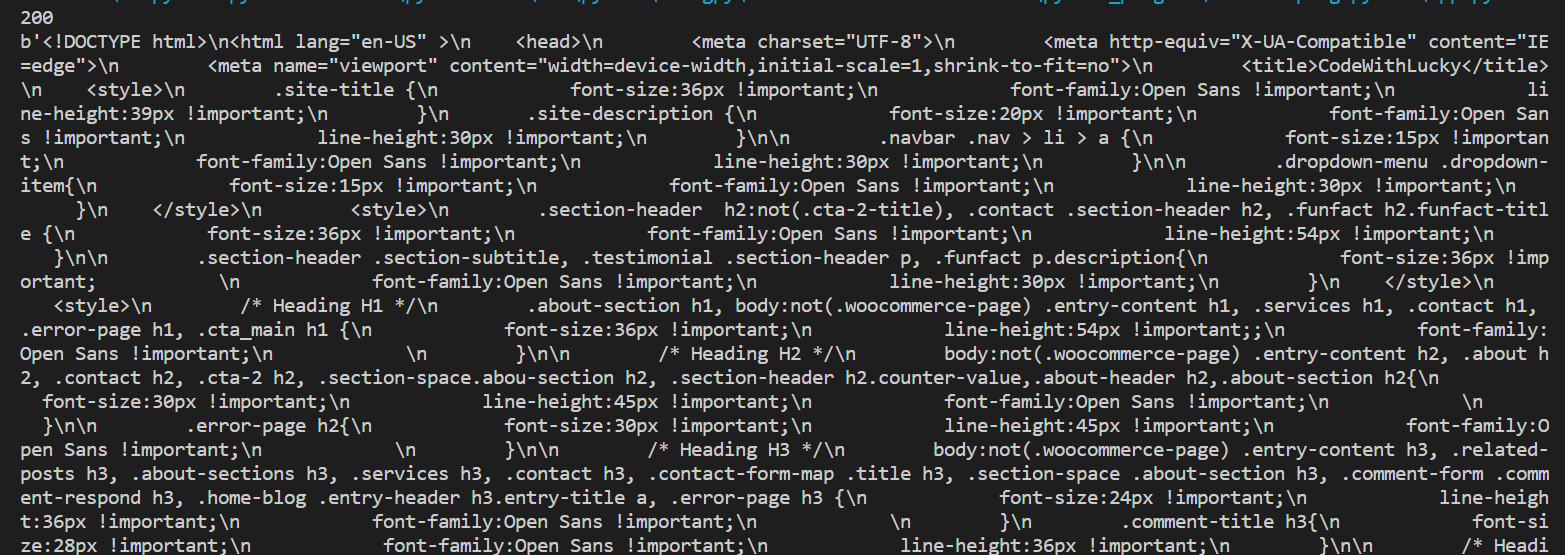
soup = BeautifulSoup(req.content material, 'html.parser')
print (soup.prettify())
Ouput: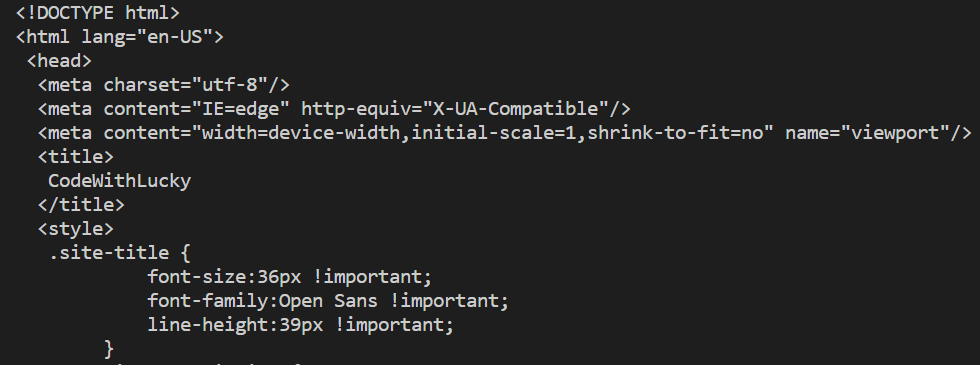
We’ve parsed and prettify response HTML utilizing prettify() but it surely’s nonetheless not usefull because it’s displaying all resposne HTML.
1. Extracting Info By Ingredient Class
Now we need to extract some particular HTML from beneath web site. We’ll extract all paragraph textual content from web page particular class.
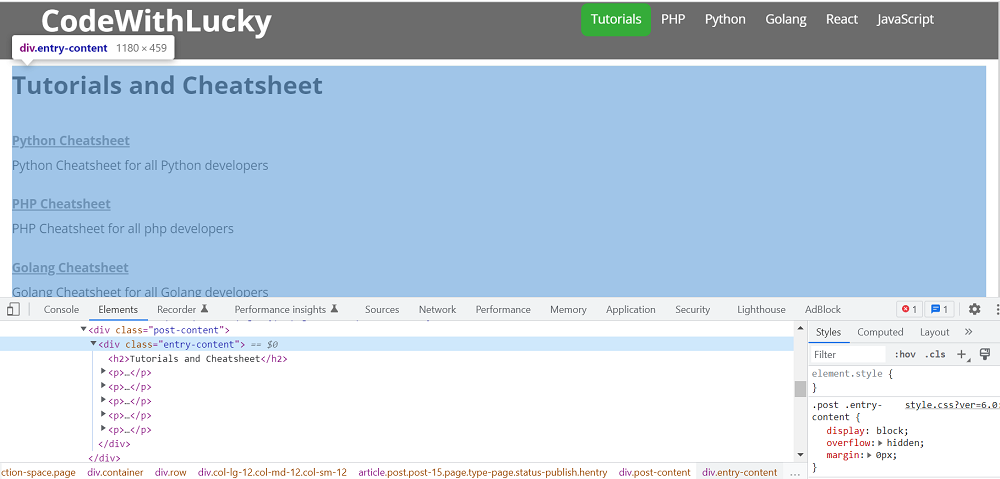
We will see in web page supply, the paragraphs are beneath <div class="entry-content">, so we are going to discover all P tags current in that DIV with Class. We’ll use discover() perform to seek out the article of that particular class from DIV. We’ll use find_all() perform to get all P tags from that object.
import requests
from bs4 import BeautifulSoup
# Passing headers if not in a position to entry as a result of mode_security
headers = {
'Consumer-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/",headers=headers)
soup = BeautifulSoup(req.content material, 'html.parser')
entryContent = soup.discover('div', class_='entry-content')
for paragraph in entryContent.find_all('p'):
print (paragraph.textual content)
Output: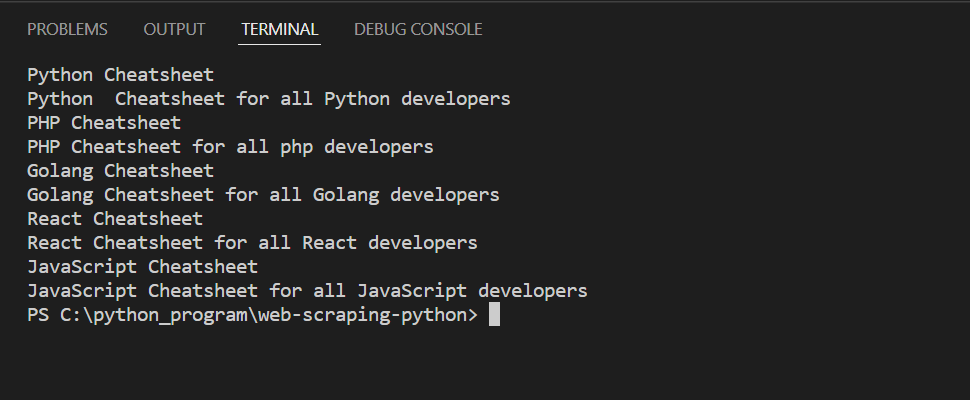
2. Extracting Info By Ingredient Id
Now will extract all high menu textual content by aspect by id. We can have following HTML supply.
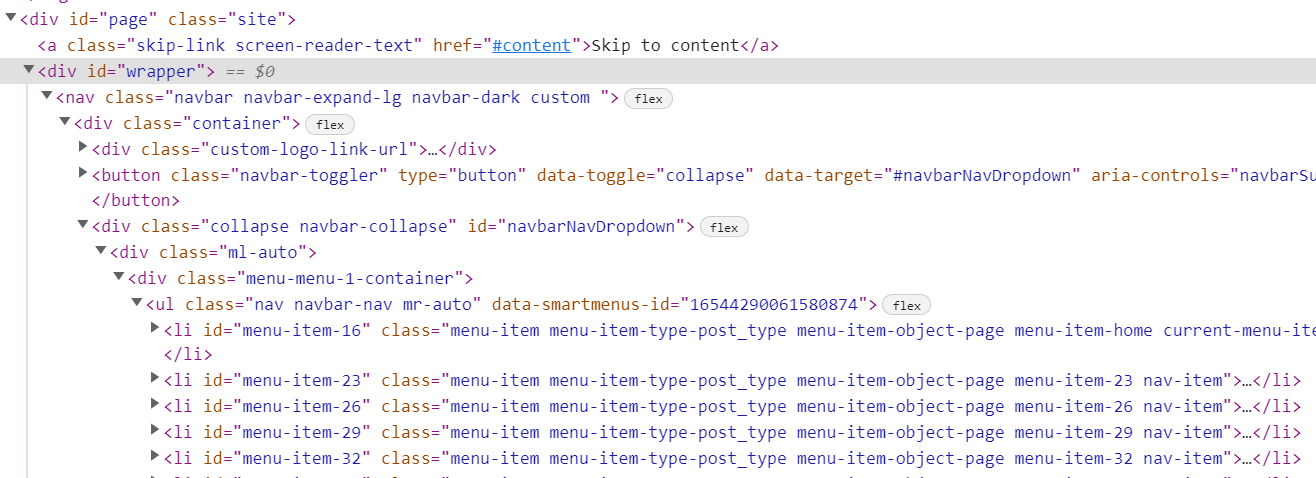
We’ll discover DIV object by id. Then we are going to discover UL aspect from that object. Then we are going to discover all li aspect from that UL aspect and get textual content.
import requests
from bs4 import BeautifulSoup
# Passing headers if not in a position to entry as a result of mode_security
headers = {
'Consumer-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/",headers=headers)
soup = BeautifulSoup(req.content material, 'html.parser')
wrapper = soup.discover('div', id='wrapper')
navBar = wrapper.discover('ul', class_='navbar-nav')
for record in navBar.find_all('li'):
print (record.textual content)
Output:
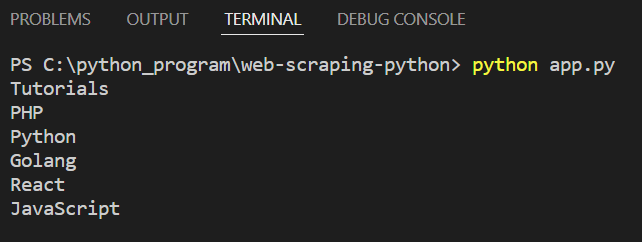
3. Extracting Hyperlinks
Now we are going to extract all hyperlinks information from a selected div.
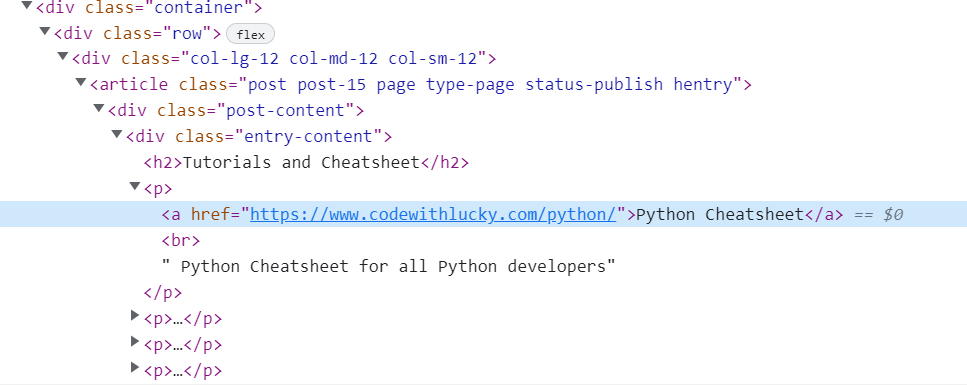
We’ll discover object of DIV with class entry-content after which discover discover all anchor a tags and loop via to get anchor href and textual content.
import requests
from bs4 import BeautifulSoup
# Passing headers if not in a position to entry as a result of mode_security
headers = {
'Consumer-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/",headers=headers)
soup = BeautifulSoup(req.content material, 'html.parser')
entryContent = soup.discover('div', class_='entry-content')
for hyperlink in entryContent.find_all('a'):
print (hyperlink.textual content)
print (hyperlink.get('href'))
Output: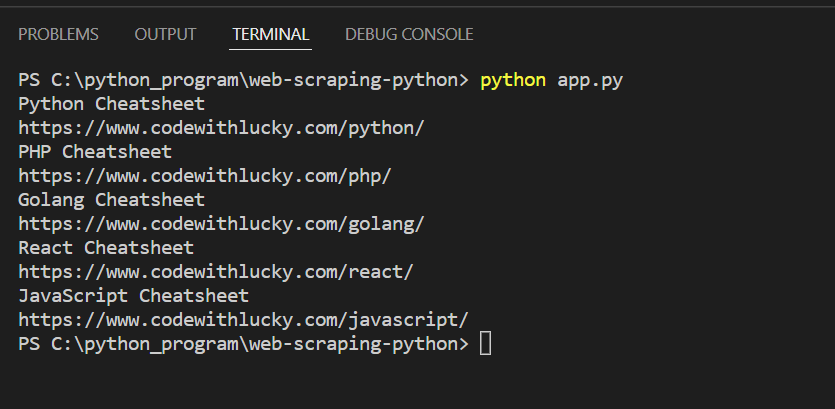
4. Saving Scraped Information to CSV
Now we are going to save scraped information to CSV file. Right here we are going to extract anchor particulars and save into CSV file.
We’ll import csv library. Then we are going to get all hyperlinks information and append into an record. Then we are going to save record information to CSV file.
import requests
from bs4 import BeautifulSoup
import csv
# Passing headers if not in a position to entry as a result of mode_security
headers = {
'Consumer-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
# Making a HTTP GET request
req = requests.get("https://www.codewithlucky.com/",headers=headers)
soup = BeautifulSoup(req.content material, 'html.parser')
anchorsList = []
entryContent = soup.discover('div', class_='entry-content')
linkCount = 1
for hyperlink in entryContent.find_all('a'):
anchor = {}
anchor['Link text'] = hyperlink.textual content
anchor['Link url'] = hyperlink.get('href')
linkCount += 1
anchorsList.append(anchor)
fileName="hyperlinks.csv"
with open(fileName, 'w', newline="") as f:
w = csv.DictWriter(f,['Link text','Link url'])
w.writeheader()
w.writerows(anchorsList)
Output: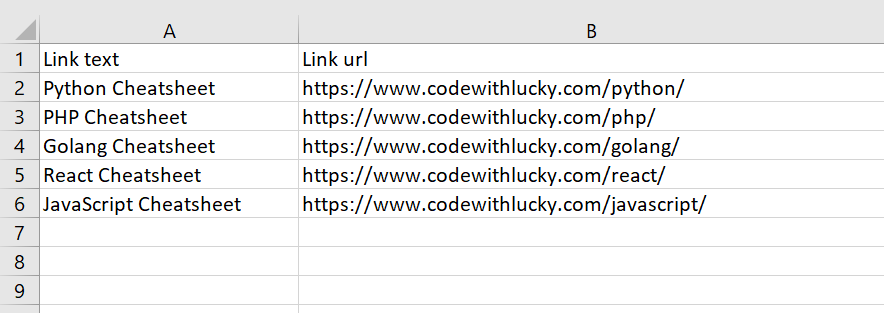
[ad_2]
Source_link