
[ad_1]
Presenting the fork of asyncpg — asynchronous PostgreSQL shopper for Python — based mostly on NumPy structured arrays
I hacked asyncpg — an asyncio PostgreSQL shopper library — to parse the SELECT-ed data from low-level PostgreSQL protocol on to NumPy structured arrays with out materializing Python objects, and averted a lot of the overhead.
It labored as much as 3x wall and 20x CPU sooner; it doesn’t forged spells to speed up the DB server. The repository to star is athenianco/asyncpg-rkt.
Increasingly rising databases select to talk PostgreSQL wire protocol, e.g., Cockroach or Crate. Granted that it’s easy, a PoC facade server in Python is lower than 200 strains. Such an enormous household of suitable DBs suggests an environment friendly Python shopper library. An analytics-first shopper library.
In one in every of my earlier weblog posts, I observed how inefficient the transition from PostgreSQL response to pandas DataFrame was. Let me remind you of the code:
pd.DataFrame.from_records(await connection.fetch("SELECT ..."))
We make many redundant actions beneath:
- Parse PostgreSQL wire protocol and create Python objects.
- Insert these Python objects into created
asyncpg.File-s. - Iterate rows and insert Python objects into NumPy arrays of
objectdtype. - Infer higher dtypes like int64, datetime64, and so forth., and convert Python objects.
- Assemble the dataframe.
Nevertheless, we all know the information varieties of the returned columns beforehand and will do a ton higher:
- Parse PostgreSQL wire protocol to typed NumPy arrays.
- Assemble the dataframe.
Profiling indicated clear bottlenecks in materializing tens of millions of Python objects solely to transform them again to the very same in-memory illustration because the PostgreSQL server despatched, ignoring the endianness. Each time we copy an object array in Pandas, we increment and decrement the reference counters of every object, which hammers the ultimate nail within the efficiency coffin.
Sadly, the a part of asyncpg which is liable for constructing the array of returned asyncpg.File -s is written in Cython and can’t be simply personalized. I needed to fork.
I thought of the next necessities:
- It have to be a drop-in substitute. Don’t break the prevailing consumer code.
- Swish degradation: fallback to Python objects when a column kind is an object (e.g., JSON).
- Deal with nulls effectively. Not all built-in NumPy dtypes assist a null-like worth similar to NaN or NaT, so we should return the positions of nulls.
- No additional dependencies besides NumPy.
- One of the best efficiency that I can organize.
Find out how to leverage the brand new superpowers
Set up asyncpg- as standard: python -m pip set up asyncpg-rkt
We name set_query_dtype() to reinforce the question string with the outcome dtype description. The dtype must be structured. The utilization of the returned array doesn’t differ a lot from the unique listing of asyncpg.File-s:
nulls are the flat indexes in arr the place we fetched nulls:
Fetching an everyday question works the identical as within the authentic library:
Moreover, asyncpg- presents an alternate “block” output mode tailor-made particularly for Pandas:
The returned array is a 1D object array-like the place every factor is a column with values:
Supposed use instances and limitations of the venture:
- The consumer ought to care concerning the efficiency. In most situations, the potential speedup just isn’t ground-shaking, so it’s in all probability not definitely worth the trouble.
SELECTa minimum of ten rows. In any other case, the profit is minuscule.- The consumer is aware of the varieties of the returned fields upfront. Any information modeling ought to come in useful, e.g., SQLAlchemy.
- These sorts are primarily primitive and map to NumPy: integers, floating factors, timestamps,
bytea,textual content,uuid, fixed-size geometry. - The consumer is aware of the utmost size of the returned bytes and strings to specify ample
S#andU#sorts. In any other case, it’s attainable to fall again to things, however the efficiency will degrade. - Both use asyncpg straight or via a skinny wrapper like morcilla. Async SQLAlchemy 1.4 and encode/databases are going to interrupt as a result of we return a tuple with a NumPy array and null indexes as a substitute of a single listing of
File-s; even when these libs survive, they repack the outcome of their File-like Python objects and can miss the purpose. - Conversion of the outcome to pandas DataFrame ought to fly.
- Don’t anticipate magic! This fork is not going to speed up the database server.
I in contrast the efficiency of 4 completely different execution modes:
min— executingSELECT 1. This mode units absolutely the minimal question execution time.dummy— we learn information from PostgreSQL and instantly drop it. The shopper doesn’t do any actual work,fetch()all the time returnsNone. This mode approximates the server processing time along with the client-server communication. It serves as the perfect, unreachable goal.report— legacy question execution, we return the listing ofasyncpg.Fileobjects as standard.numpy— mode. We return the structured NumPy array and the listing of null indexes.
My Postgres server was operating regionally, and I linked to localhost:5432. The question was:
SELECT ... FROM generate_series(1, size)
- the place
sizeis the variety of similar rows to be returned ...are hardcoded two booleans (5 bigints, one float4, 4 timestamps, two instances, two bytea-s of size 16, and two texts of size 5 and 10)
I measured numerous size-s from 100 to 50,000. The benchmark closely makes use of the superb pytest-benchmark plugin for pytest. I ensured a number of warmup iterations as well the ready assertion correctly.
The tip-to-end question execution is as much as 3x sooner in “numpy” mode versus “report.” If we subtract the immutable “dummy” time, the pure CPU time speedup reaches 22x. The usual deviation of the “numpy” execution time is identical as “dummy”, whereas “report” jumps significantly increased. We win about 120ms on 50k rows, as much as 250ms when it fluctuates most violently.
After all, the real-world speedup can be lower than 3x as a result of any sensible question spends extra time within the PostgreSQL server. I don’t promote snake oil. Absolutely the delta ought to stay the identical, although.
Beneath are thepy-spy --native profiles for comparability. The primary is “report”, the second is “numpy”. The profile exhibits that parsing pgproto to Python’s datetime is a major bottleneck.
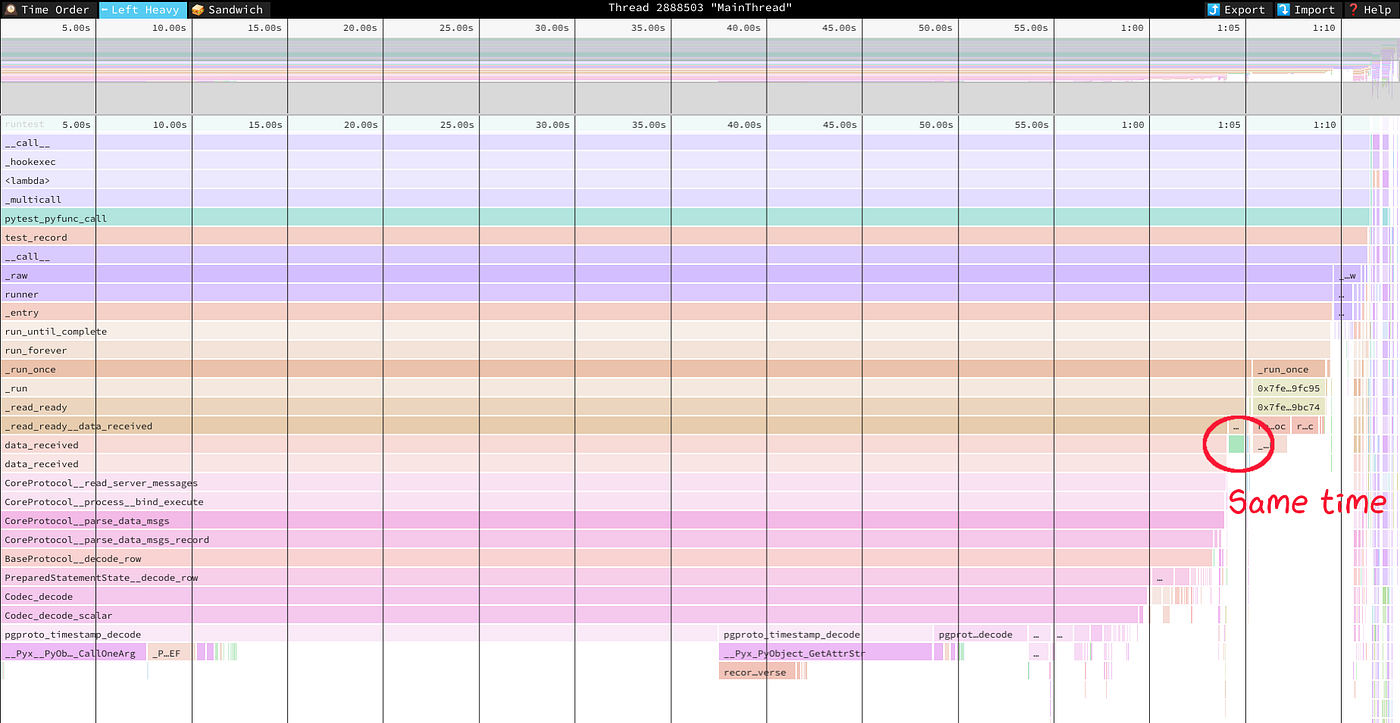
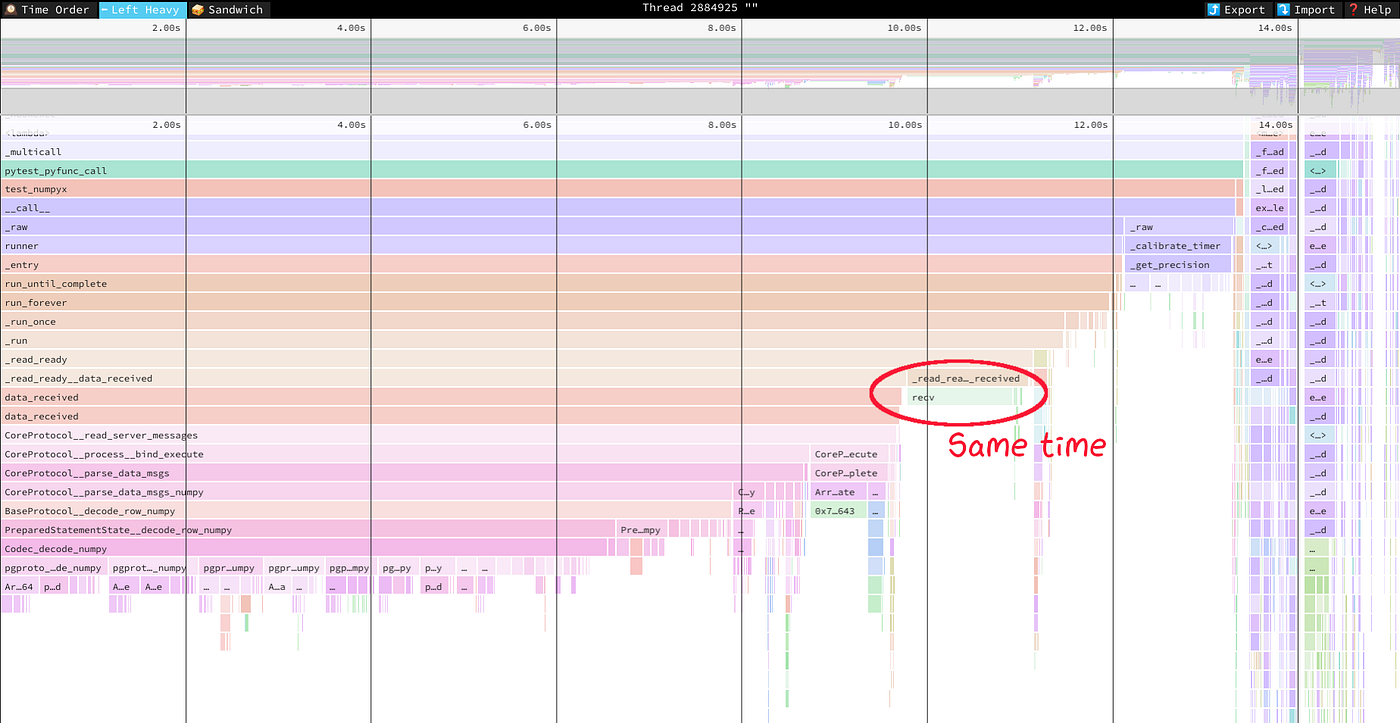
The supply code of the benchmark is on GitHub.
“Question augmentation” works by prepending the pickled dtype. The backend code in native asyncpg unpickles again. That’s not as environment friendly as passing a reference straight, however I didn’t need to change any public interfaces, even backward-compatible. If asyncpg will get known as via a wrapper library, no one is keen to ahead the reference passing there, too.
The worth to pay is a few deserialization overhead. Given the supposed common variety of fetched rows, it ought to be negligible.
The unique Cython code is already fairly quick. It taught me a number of intelligent tips with extension lessons like preallocation — @cython.freelist or disable the rubbish assortment — @cython.no_gc. I discovered just one place for enchancment: the frb_check() buffer overrun checks ought to be inlined straight as a substitute of hoping that Cython will do “the precise factor.”
The slowdown is the consequence of Cython’s shenanigans of exception forwarding. The pure Python counterpart is twisted in some locations. I smile each time I’ve to hint the question circulation in asyncpg.Connection and step in via:
execute()_execute()__execute()_do_execute()executor()
asyncpg- depends on NumPy’s structured arrays. They’re fixed-shape C constructions with non-compulsory alignment. NumPy exposes the construction fields each by index and by title. Internally, NumPy retains the plain listing and the dictionary mappings to the nested dtypes and offsets.
PostgreSQL streams rows to the shopper, and we don’t know what number of we’ll fetch till we fetch all of them. It’s unimaginable to resize a NumPy array dynamically, equally to appending File-s to an inventory, and therefore we’ve got to allocate page-aligned evenly sized chunks and concatenate them in the long run.
Sadly, these additional allocations result in double peak reminiscence consumption and tons of memcpy() from the chunks to the ultimate vacation spot.
PostgreSQL sends timestamps and timedeltas as 64-bit integers with microsecond precision. NumPy permits numerous models in datetime64 and timedelta64, e.g., days, seconds, nanoseconds.
Subsequently we should carry out the unit conversion by integer multiplication or division. Profiling indicated that the integer division is just too gradual. It’s nothing new, in fact. Fortunately, there’s a trick from the sequence of Doom’s quick inverse sq. root and the C header-only libdivide that’s bundled along with numpy≥1.21.
I wrapped numpy/libdivide/libdivide.h in Cython, and it labored like a “magic” allure. One other essential step is adjusting zero, aka the epoch. PostgreSQL’s zero is 2000–01–01, and NumPy’s zero is 1970–01–01, so we should add 30 years to every worth.
PostgreSQL sends strings in UTF-8. NumPy, on the opposite finish, expects UCS-4 for the sake of simpler vectorization, I suppose. We’ve to recode. CPython exports related features, however all of them anticipate Python string or byte objects, which might kill the efficiency.
I tailored the implementation from MIT-licensed fontconfig: FcUtf8ToUcs4. It really works moderately quick; the algorithm is easy. The fork has an possibility to repeat strings on to S# dtype — nice for ASCII-restricted textual content.
I needed to resolve the difficulty with nulls. We’ve to assist them with out sacrificing efficiency. Every time we encounter a null, we append the flat index to an inventory and write a NaN surrogate to the array chunk.
- For float32 and float64, that may be a real NaN.
- For datetime64 and timedelta64, that may be a NaT that behaves equally.
- For objects, we write
None. - For integers, we write the minimal worth given the variety of bits.
- For
S#, we fill with0xFF. - For
U#, we fill with0x00.
Clearly, any of the talked about values may be official, so the one assured test for nulls is to scan the returned null indexes.
What occurs if the consumer units the unsuitable dtypes? They need to catch a useful exception:
asyncpg.pgproto.pgproto.DTypeError: dtype[10] = <U20 doesn’t match PostgreSQL textual content of measurement 21
Staying on the kind matter, I’m utilizing an undocumented constructor argument of np.dtype to specify the column output mode:
Each dtype carries a metadata attribute that’s both None or a read-only (mappingproxy) dictionary set on the building time.
Relating to the column output, asyncpg- teams columns of identical dtype collectively and allocates reminiscence in blocks, harking back to how Pandas does (used to do?) it. The user-facing arrays are the block views. The block origin is referenced by the base attribute of the column array.
It requires fairly an additional effort. The Cython code compilation presently breaks with out NumPy. It could be attainable to make NumPy an non-compulsory dependency. If the neighborhood requests the merge and the maintainers of asyncpg are benevolent, then yeah, let’s rock.
I’ve described asyncpg- —my backward-compatible fork of asyncpg, a Python asyncio shopper for PostgreSQL.
asyncpg- parses the SELECT-ed data from low-level PostgreSQL protocol on to NumPy structured arrays with out materializing Python objects, thus avoiding a lot overhead. It’s as much as 3x wall and 20x CPU sooner. The repository is athenianco/asyncpg-rkt.
[ad_2]